| [테크칼럼] 초거대 언어 모델의 보안위협과 설명가능한 인공지능의 역할 | 2024.01.08 |
환각, 편향, 저작권 및 개인정보 침해, 악의적 사용 등의 문제점과 해결방안 제시
설명가능한 AI 기술 적용과 함께 AI 모델의 판단 이해하는 것도 중요 [보안뉴스=고기혁 KAIST 사이버보안연구센터 AI보안팀장] 오픈AI(OpenAI)에서 선보인 챗GPT(ChatGPT)가 2022년 11월 처음 등장한 이래 2023년은 1년 내내 생성형 AI(Generative Artificial Intelligence)와 초거대 언어모델(LLM : Large Language Model)이 보안의 핵심 키워드로 자리매김했다. 구글의 바드(Bard)와 제미니(Gemini), 메타의 라마(LLaMa) 등 미국산 초거대 언어모델의 서비스 시작과 함께 국내에서도 네이버의 하이퍼클로바 X(HyperClova X), LG의 엑사원(EXAONE) 2.0, 삼성전자의 가우스(Gauss) 등 한국어를 주 언어로 하는 초거대 언어 모델 서비스를 공개하는 등 관련 기술 개발에 아낌없는 투자가 이루어지고 있다. 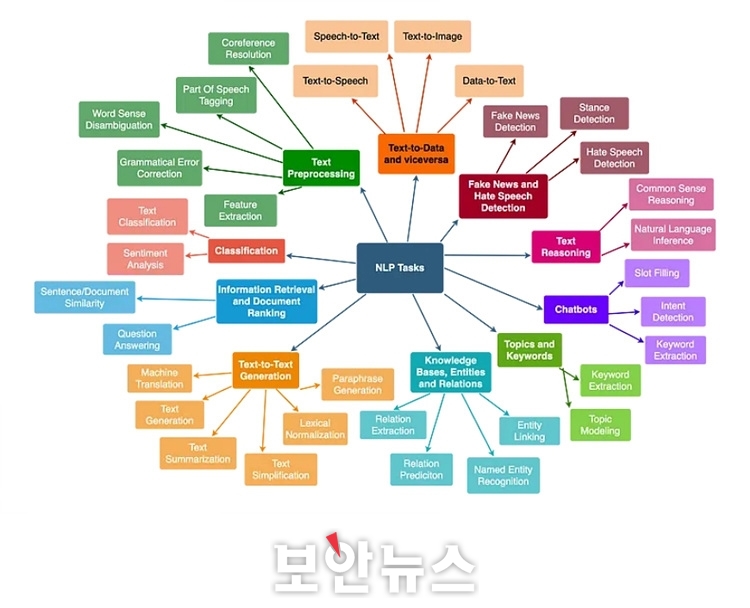 ▲다양한 종류의 자연어 처리(Natural Language Processing, NLP) 태스크[자료=카이스트 CSRC] 이같은 추세에 힘입어 몇몇 연구자들은 초거대 언어 모델의 눈부신 성공이 그간 갈망해 왔던 인공 일반지능(AGI : Artificial General Intelligence) 개발에 있어 중요한 첫 걸음으로 자리매김할 수 있지 않을까 기대를 품고 다양한 연구를 수행하고 있다. 실제로 올해 ChatGPT 3.5의 업그레이드 버전으로 공개된 ChatGPT 4.0의 경우 미국의 대학 및 대학원 입시 시험인 SAT와 GRE 뿐만 아니라, 수학, 생물, 통계, 심리학 및 변호사 시험까지 폭넓은 분야에서 뛰어난 지식을 습득했다는 것을 입증한 바 있다. 하지만 이처럼 하루가 다르게 발전하고 있는 초거대 언어 모델은 여타 모든 시스템이 그러하듯 완벽과는 다소 거리가 있다. 이러한 불완전성의 대표적인 예로, 초거대 언어 모델이 거짓된 정보를 사실인 양 제시하는 환각(hallucination) 현상에서 자유롭지 못하다는 문제가 있다. 초거대 언어 모델은 그 작동 원리 상 ‘확률적으로 그럴 듯한’ 단어들을 나열하기 때문에 생성하여 출력하는 텍스트의 진위 여부를 파악하기 어려운 것이다. 환각 현상은 구글에서 개발한 언어 모델 바드(Bard)의 시연 화면에서도 발견되어 논란을 빚은 바 있다. 이어 피싱 메일 생성 등 초거대 언어모델을 악의적인 의도로 사용하거나 사용자 개인정보나 저작권을 보호받는 데이터를 무단으로 사용하고 유출하는 등 초거대 언어 모델의 학습에서 활용까지 여러 종류의 보안 위협이 존재한다. 연구자들은 초거대 언어 모델 활용 시 주요 보안 문제점과 그에 대한 잠재적 해결방안을 다음과 같이 제시했다. 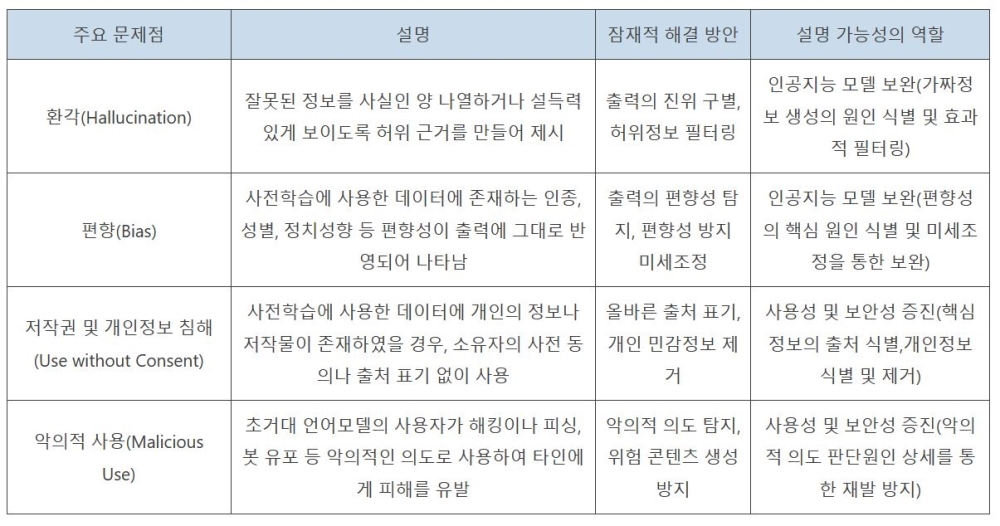 ▲초거대 언어 모델 활용 시 주요 보안 문제점, 잠재적 해결 방안 및 설명 가능성의 역할 이 같은 문제점들은 주로 초거대 언어 모델이 어떠한 지식을 학습했으며, 어떤 과정을 통해 출력을 도출했는지 사람이 명확하게 이해하지 못하기 때문에 발생한다고 할 수 있다. 따라서 연구자들은 초거대 언어 모델에 설명 가능성을 부여해 당면 문제를 부분적으로 해결 가능할 것으로 기대하고 있다. 여기서는 초거대 언어 모델이 지니는 보안 위협을 완화하고자 활용할 수 있는 설명가능한 인공지능 기술에 대해 △기울기 기반 설명(Gradient-based Explanation) △어텐션(Attention) 기반 설명 △은닉 상태 프로빙(Probing) 등 세 가지 예를 들어 소개한다. AI의 출력에 대한 설명은 주어진 AI 태스크에 따라 그 의미가 달라지기 때문에 설명 가능한 인공지능 기법도 자연어 처리 태스크의 종류만큼 다양하다고 생각할 수 있다.  ▲기울기 기반 설명(Gradient-based Explanation)의 예시[자료=카이스트 CSRC] 먼저, ‘기울기 기반 설명(Gradient-based Explanation)’ 기법은 인공지능 모델의 입력 요소(특성)가 모델의 출력을 도출하는데 있어 가지는 영향도를 기울기로 계산하는 방법으로, 컴퓨터 비전 분야를 중심으로 다양한 설명 기법이 개발돼 왔다. 컴퓨터 비전 분야에서 입력 이미지의 각 픽셀에 영향도를 부여했다면, 자연어 처리 태스크를 수행하는 언어 모델에서는 입력을 구성하는 토큰(Token) 혹은 단어 각각에 대해 영향도를 부여해 출력을 설명할 수 있다. 언어 모델의 출력한 텍스트에 대한 기울기 기반 설명의 예시를 보면, 유럽연합에 어떤 국가들이 소속됐는지를 나열하는 프롬프트에서 ‘countries’와 ‘European’과 같은 중요 키워드가 각각 5% 이상의 영향도를 가졌음을 확인할 수 있다. 이어 오스트리아, 벨기에, 불가리아 등과 같이 이미 출력된 국가도 실제 출력인 덴마크에 영향을 주는 것을 확인할 수 있다. 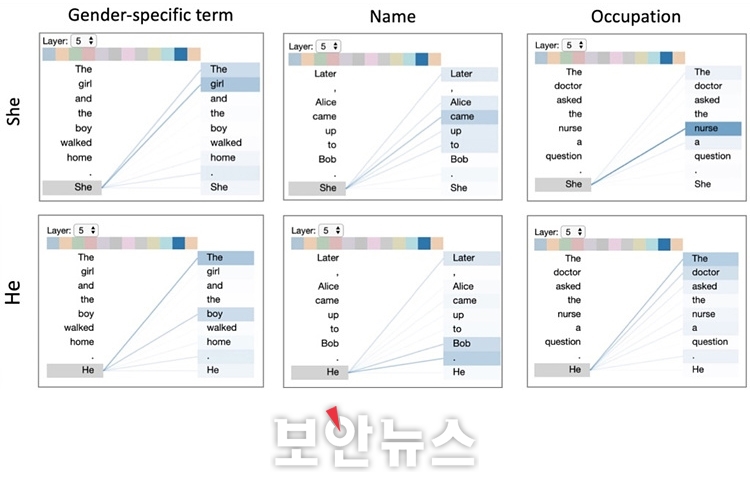 ▲어텐션 기반 설명(Attention-based Explanation)의 예시[자료=카이스트 CSRC] 다음으로 ‘어텐션(Attention) 기반 설명’ 기법을 살펴보면, 오늘날 대부분의 언어 모델은 트랜스포머(Transformer)로 구성됐다. 트랜스포머는 입력 토큰에 대해 셀프 어텐션(Self-Attention) 메커니즘을 반복적으로 적용해 출력을 계산하는 구조체로, 모델 내의 각 층에서 모든 입력 단어가 다음 단어의 예측에 어느 정도 연관됐는지를 어텐션 가중치(Attention Weight)로서 계산하게 된다. 이처럼 계산된 어텐션 값은 자연스럽게 언어 모델이 어떻게 작동하는지에 대한 설명으로 해석할 수도 있다. 어텐션 기반 설명의 예시를 보면, 각각 주어진 문장의 다음 단어로 ‘She’와 ‘He’가 선택됐을 때, 성별에 의해 지칭하는 대상, 이름, 그리고 직업 관계를 올바르게 연관지어 준다. 한 가지 주목할 점은 언어모델이 마지막 열에서 ‘She’가 선택됐을 때는 ‘nurse’를, ‘He’가 선택됐을 때는 ‘doctor’를 더 강하게 연관 짓는다는 사실이다. 이는 언어 모델이 직업에 있어 성적 편견을 학습한 것으로, 이처럼 어텐션 기반 설명은 언어 모델이 편향된 데이터로 학습되거나 특정 그룹의 편견이 있지는 않은지 사전에 검토하는 데에도 활용될 수 있다. 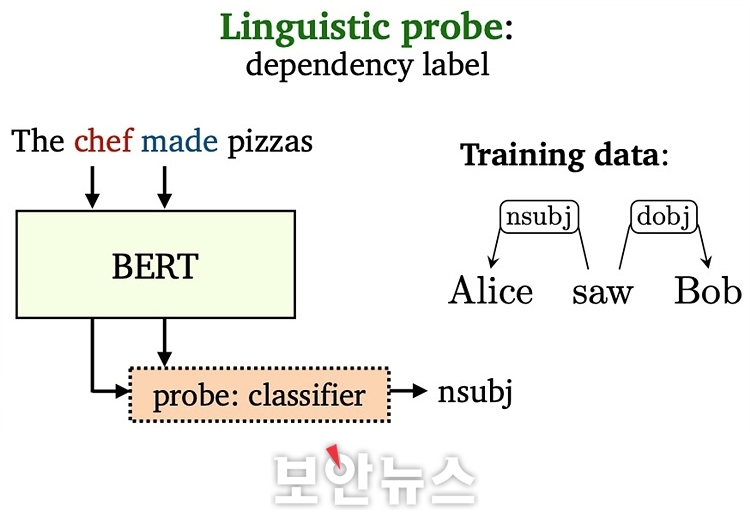 ▲언어 모델에 대한 은닉 상태 프로빙(Hidden State Probing)[자료=카이스트 CSRC] 다음으로 ‘은닉 상태 프로빙(Hidden State Probing)’이 있다. ‘프로빙’이란 언어 모델이 주어진 태스크 이외에 일반적인 언어 지식을 학습했는지를 확인하는 과정을 의미한다. 그 가운데 은닉 상태 프로빙은 언어 모델이 출력을 생성하는 중간 과정에서 계산되는 은닉층(Hidden Layer)의 상태, 즉 임베딩 값을 기반으로 판별기(Classifier)를 학습시켜 언어 모델이 과연 올바른 지식을 학습하고 있는지를 테스트하는 기법이다. 은닉 상태 프로빙을 사용하면 언어 모델이 단순히 주어진 태스크에만 최적화되는 것이 아니라 일반적인 언어적 구조를 이해하고 해석할 수 있는지, 덧붙여 일반적 사실을 학습했는지 여부 등을 테스트할 수 있게 된다. 지금까지 초거대 언어 모델의 보안 위협과 설명가능한 인공지능에 대해 살펴봤다. 설명가능한 인공지능 기술을 적용하는 것만으로 초거대 언어 모델이 내포한 보안 문제를 모두 해결할 수는 없겠지만, 점차 복잡해지는 인공지능 모델의 판단을 더 잘 이해하는 것은 보다 안전한 초거대 언어 모델 개발 및 활용에 있어 중요한 첫걸음이 되지 않을까 생각해본다. 초거대 언어 모델과 관련해서는 설명가능한 인공지능 기술 이외에도 검색 증강 생성(RAG : Retrieval Augmented Generation) 등 보안성을 증진시키는 혁신적인 원천 기술이 하루빨리 상용화되길 기대한다. [글_ 고기혁 박사/KAIST 사이버보안연구센터 AI보안팀장] <저작권자: 보안뉴스(www.boannews.com) 무단전재-재배포금지> |
|
|
|