| 일반 물체인식에 도전! | 2009.06.11 |
일반 물체인식이란 실제 세계의 장면을 제약이 없는 상태에서 촬영된 화상 안에서 어떤 물체가 영상 내에 존재하는지, 그리고 어떤 장면인지를 일반적인 명칭으로 컴퓨터가 인식하는 것이다. 최근 컴퓨터의 발전에 의해 대량의 데이터를 고속으로 처리하는 것이 가능해 졌으며, 또한 기계 학습 분야에서 연구된 학습방법이 일반 물체인식에 적용할 수 있게 되었기 때문에 많은 일반 물체인식 방법이 제안되었다. 여기에서는 2008년 6월에 개최된 화상 센싱 심포지움의 Organized Sessions ‘일반 물체인식에 도전!’의 내용을 정리하여 일반 물체인식은 어떤 기술이고 현재 어디까지 발전했는가에 대하여 기술하고자 한다.
머리말 오늘날 디지털 카메라의 보급으로 디지털 사진이나 동영상이 우리들의 일상에 대량으로 존재하며 이러한 디지털 영상에는 여러 가지 장면이나 물체가 촬영되어 있다. 이처럼 실제 장면을 제약이 없는 상태에서 촬영한 화상 중에서 어떤 물체가 화상 내에 존재하는지, 그리고 어떤 장면인지를 일반적인 명칭에서 컴퓨터가 인식하는 것을 일반 물체인식이라 부른다. 일반 물체인식을 해석하려면 컴퓨터의 연산능력이 중요한데, 종래의 컴퓨터에서는 대량의 데이터 처리가 어려워 적용이 불가능했다. 하지만 최근 컴퓨터가 발전하면서 대량의 데이터를 고속으로 처리하는 것이 가능해졌고, 또한 기계 학습 분야에서 연구된 학습 방법이 일반 물체인식에 적용할 수 있게 되었기 때문에 많은 방법이 제안되어 있다. 그 중에서도 Viola&Jones의 얼굴검출 방법이나 Bag-of-Keypoints에 의한 화상 분류 등과 같이 통계적인 기계 학습법을 사용한 일반 물체인식 방법이 제안되어 있다. 또한 각 방법의 객관적인 평가를 하기 위해 공통 데이터 세트가 구축되어 최근에는 일반 물체인식 연구가 한층 더 활발하게 이루어지고 있다.
일반 물체인식이란
일반 물체인식의 어려움 일반 물체인식을 어렵게 하는 주요 요인으로서 일반적인 명칭을 가리키는 카테고리가 방대하다는 것과 동일 물체 카테고리 내의 변화(Variation)의 다양함을 들 수 있다. 일반적인 명칭에 의한 카테고리 분류를 하는 경우 그 카테고리 수는 10,000에서 30,000이 된다고 한다. 또 카테고리 내에는 서브클래스(Subclass)가 존재하는 경우가 있다. 예를 들면 ‘자동차’라는 카테고리에는 ‘세단(Sedan)’, ‘왜건(Wagon)’, ‘트럭’과 같은 형상의 차이, ‘헤드라이트’, ‘프런트 유리’와 같은 부위의 차이에 따른 서브클래스로 나열할 수 있다. 때문에 어디까지를 대상 카테고리로 할지 명확하게 정의하는 것이 어렵다. 한편 동일 물체에서도 시점의 변화, 조명 변화, Occlusion, 스케일 변화, 물체의 변형 등에 의해 모습이 크게 변화하기 때문에 이와 같은 조건 하에서 인식하는 것은 어려운 문제이다. 또한 인식 대상의 물체가 화상 중의 어디에 존재하고 있는가를 검출할 필요도 있다. 일반 물체인식 문제에서는 모습의 변화에 불변하고 또한 물체 이외의 배경 정보에 영향을 받지 않는 특징 추출과 변화를 많이 포함한 학습 데이터 세트의 구축이 중요해진다.
일반 물체인식의 간략화 일반 물체 인식은 불확정한 요소가 많기 때문에 매우 어려운 문제이다. 그런 까닭으로 일반 물체인식 문제에 제약을 두는 것으로 문제를 간략화한다. 간략화한 일반 물체 인식 문제의 예를 이하에 나타낸다(그림 2).
이처럼 일반 물체인식에서는 로컬라이제이션과 카테고라이제이션의 2가지의 제약을 도입함으로써 현상에서는 문제를 간략화하여 해석하고 있다. 이 2가지를 동시에 해결하는 방안이 실현 가능하면 일반 물체인식을 해결하는 것이 되기 때문에 로컬라이제이션 문제와 카테고라이제이션 문제는 일반 물체인식 문제에서 중요한 과제라 할 수 있다. 여기에서는 최근 연구가 활발하게 이루어지고 있는 로컬라이제이션 문제인 Detection(물체 검출)과 카테고라이제이션 문제인 Object Categorization (화상 분류)에 대하여 소개한다.
물체 검출 =‘Find all the Xs’ 물체 검출이란 얼굴이나 사람 등의 특정의 일반 물체가 화상 중의 어디에 있는지를 검출하는 것이다. 하나의 검출기에서는 특정 물체밖에 검출할 수 없지만, 각 물체 카테고리에 대응한 검출기를 작성하여 병렬로 동작시킬 수 있으면 일반 물체인식을 실현하는 것이 가능하다고 생각된다. 물체 검출에서 가장 큰 문제였던 얼굴 검출은 1990년대 후반부터 Raster Scan 주사(走査)에 의한 얼굴 검출법의 연구가 이루어져 현재에는 휴대전화나 디지털 카메라 등에 실용화되어 있다. Rowley는 얼굴 영역의 크기에 영향을 받지 않고 검출 가능한 뉴럴 네트워크(Neural Network)를 이용한 얼굴 검출 방법을 제안하고 그 후 통계적 학습방법을 사용한 얼굴 검출의 연구가 활발하게 이루어지게 되었다. Rowley에 의한 얼굴 검출법에서는 화상 전체에서 특징량을 추출하기 위해 조명 변화나 형상 변화에 대하여 검출이 곤란해지는 경우가 있으며, 2000년 이후에서는 통계적 학습 방법과 국소 특징량의 조합으로 물체 검출하는 방법이 주류가 되었다. Viola들은 국소 특징량으로서 영역의 명도차를 특징으로 하는 Haar-like 특징량을 다수 조합시켜 얼굴 검출기를 구축하였다(그림 3). 검출기에는 AdaBoost를 사용하는 것으로 국소 특징량의 다수 조합 가운데에서 식별에 최적의 특징량을 자동 선택하고 있다. 이로써 큰 특징 차원수라도 고속 처리가 가능해지며 고정밀도의 얼굴 검출을 실현하였다. 2005년에는 사람 검출에 유효한 기울기 정보를 이용한 특징량으로서 HOG(Histograms of Oriented Gradients)가 Dalal들에 의해 제안되었다. HOG는 SIFT(Scale Invariant Feature Transform)와 마찬가지로 국소 영역에서 휘도의 기울기 방향을 히스토그램화한 특징량이다. SIFT와 유사한 특징량의 기술을 하지만 SIFT는 특징점에 대하여 특징량을 기술하는 것에 비하여 HOG에서는 어떤 일정한 영역에 대한 특징량을 기술한다. 때문에 대략적인 물체 형상을 표현하는 것이 가능하며 사람 검출이나 자동차 검출 등의 일반 물체인식 등에 사용되고 있다(그림 4).
화상 분류 =‘Whats this?’ 화상 분류는 그 화상이 어떤 물체 카테고리를 포함하는 화상인지를 인식하는 문제이다. 최근 대상 물체의 구조 정보(위치 정보)를 아예 사용하지 않고 화상을 국소 특징량의 집합으로 간주하는 것으로 인식 물체를 표현하는 Bag-of-Keypoints라 불리는 방법이 제안되고 있다. Bag-of-Keypoints는 문서 분류 방법인 Bag-of-words를 화상에 적용한 방법이다. Bag-of-words는 문장을 단어 집합으로 간주하여 단어의 어순을 무시하여 그 빈도로 문장 분류를 한다. 마찬가지로 Bag-of-Keypoints에서는 화상을 국소 특징량(Keypoint)의 집합으로 간주하여, 그 위치 정보를 무시하며 화상인식을 한다. Bag-of-Keypoints에서 국소 특징량에는 스케일과 회전에 대하여 불변의 특징량을 얻을 수 있는 SIFT가 사용되고 있다. SIFT는 화상 내의 대상물이 스케일 변화나 회전에 영향을 받지 않는 특징을 기술할 수 있기 때문에 대상물의 크기나 회전이 미지인 물체 카테고리 분류의 입력 특징에 적합하다. 그림 5에 Bag-of-Keypoints에 의한 화상 분류의 흐름을 나타낸다. Bag-of-Keypoint에서는 사전에 각 물체 카테고리의 학습 화상에서 SIFT 특징량을 추출하여 국소 특징량을 벡터(Vector) 양자화한다.
이 벡터 양자화된 특징량은 Visual Word나 Visual Alphaber로 불리어 물체 카테고리마다의 Visual Word의 히스토그램을 사용하여 학습 화상군에서 식별기를 작성해 둔다. 1장의 입력 화상에서 얻어진 Visual Word의 히스토그램을 그 입력 화상의 특징량으로 각 물체 카테고리의 식별기에 입력하여 판정한다.
평가 데이터 세트와 워크숍 최근 일반 물체인식의 연구가 활발하게 이루어지게 된 요인의 하나에는 공통 데이터 세트를 사용하여 평가하는 것이 가능해 진 것을 들 수 있다. 화상 분류의 일반적인 평가 데이터베이스로서 Caltech101/256이 있다. Caltech101은 101종류의 카테고리로 구성되어 있으며 Google Image Search를 사용하여 모은 9,144장의 화상 데이터를 분류, 물체의 방향과 크기가 거의 갖추어져 있다. 또한 각 카테고리 화상 수는 31장에서 800장으로 불규칙하다. 이에 비하여 Caltech256에서는 카테고리 256종류에 3만607장의 화상을 수집해 방향이나 크기를 통일하지 않아도 되는 데이터베이스를 구축하여 Caltech101과 함께 공개되어 있다. 현재 화상 분류 방법의 비교에서는 이 Caltech256에 의한 평가가 일반적이다. Caltech 101/256 이외의 데이터베이스에는 LabelMe Dataset, Graz-02 Database, NORB DATA SET가 있으며 이들도 공개되어 있다. 또한 이들 평가 데이터베이스를 사용한 일반 물체 인식의 벤치마크 워크숍이 개최되어 있다. 일반 물체인식의 벤치마크 워크숍은 PSCAL, Challenge, TRECVID 등이 있다. PASCAL Challenge Visual Object Class는 유럽의 패턴 인식, 기계 학습 커뮤니티의 PASCAL(Pattern Analysis. Statistieal Modeling and Computational Leaning)에 의해 주최되어 있는 일반 물체인식의 콘테스트로 학습용 화상과 평가용 화상이 주어져 화상 중에 10종류의 물체(Bicycle, Bus, Car, Cow, Dog, Horse, Motorbike, Person, Sheep)가 화상에 포함되어 있는가를 판별하는 Classification과 어디에 포함되어 있는가를 구하는 Detection의 2가지 과제가 있다. 게다가 CVPR2007과 ICCV2005에서는 Recognizing and Learning Object Categories라는 지도서(Tutorial)나 워크숍이 개최되어 있다.
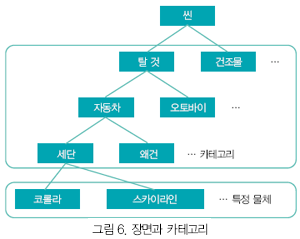
일반 물체인식의 실현을 위한 과제 Haar-like나 HOG 특징량을 사용한 물체 검출 방법이나 Bag-of-keypoints에 의한 화상 분류 방법의 제안에 따라 일반 물체인식은 새로운 국면을 맞이했지만 실용화에는 아직 해결해야 할 문제가 많이 남아 있다. 앞으로는 인식하는 카테고리 수가 한층 더 증가할 것으로 보이며 방법의 고속화와 함께 더 나은 인식율의 고정밀도화가 기대되고 있다. 현재의 물체 검출이나 화상 분류 방법은 기본적으로 단일 대상물을 인식하고 있다. 그러나 실제 장면에서는 여러 가지 물체가 포함되어 있으며 그들 물체에는 대응하는 클래스와 고유명사가 있다(그림 6). 그렇기 때문에 인식률을 높이려면 장면이나 물체간의 관계성을 고려한 탑 다운(Top Down)에 의한 정밀도 향상을 지향하는 방법과 특정 물체의 인식 정밀도를 향상시킴으로서 상위 계층인 물체 카테고리의 인식률을 향상시키는 보텀 업(Bottom Up)에 의한 방법이 중요하다고 할 수 있다. 물체 간의 관계를 이용한 인식 방법은 문맥(Context)을 이용한 인식 방법으로서 Torralba들은 Part, Object, Scene의 관계를 그래피컬 모델에 의한 확률 모델로 표현하는 방법을 제안하고 있다. Hoiem들은 화상에서 소실점을 사용하여 간단한 3차원 복원을 하여 3차원 상의 문맥을 이용하는 방법을 제안하고 있으며 CVPR2006의 Best Paper에 채용되어 있다. 이처럼 화상 상의 문맥, 3차원 상의 문맥, 오브젝트 간의 문맥을 이용하는 방법 등이 제안되어 일반 물체인식에 도입되기 시작했다.
종래에는 카테고리 분류와 물체 검출은 다른 문제로 취급되고 있었지만, 국소 특징량인 HOG를 피라미드화 하여 각 부품의 위치 관계를 고려함으로써 카테고라이제이션 문제와 로컬라이제이션 문제를 동시에 해석하는 방안이 2008년에 제안되어 새로운 국면을 맞이하고 있다.
맺음말 이 원고에서는 일반 물체 식은 어떤 문제인가, 그리고 현재 해결되어 있는 문제에 대하여 기술하였다. 얼굴 검출이나 사람 검출에 대표되는 물체 검출이나 Bag-of-Keypoints에 따른 화상 분류 방법은 통계적인 학습 방법과 특징량의 진화가 동반되어 유효한 방법이 제안되고 있다. 앞으로는 특징량 간의 공기(共起: 함께 관계를 맺음)나 문맥의 이용에 의한 인식 능력의 고정밀도화와 보다 많은 물체 카테고리를 대상으로 하기 위한 처리의 고속화가 한층 더 기대된다. 일반 물체인식은 컴퓨터 비전 분야에서 궁극적인 과제이며 연구자, 개발자 간에 문제를 공유하여 이와 같은 어려운 문제에 도전해 나감으로써 이러한 분야가 크게 전진해 나갈 것을 기대한다. <글 : 김 성 태 | 후지요시 히로노부(hf@cs.chubu.ac.jp) / 츄부 대학> [월간 시큐리티월드 통권 제148호 (info@boannews.com)] <저작권자: 보안뉴스(www.boannews.com) 무단전재-재배포금지> |
|
|
|
 일반 물체인식이란 제약이 없는 실제 세계 장면의 영상에 대하여 컴퓨터가 그 안에 포함된 물체를 일반적인 명칭으로 인식하는 것이다. 일반 물체인식의 최종적인 목표는 ‘그림 1’에 나타내듯이 분할(Segmentation)된 각 영역에 대하여 물체 카테고리의 라벨을 붙이는 것이라 할 수 있다.
일반 물체인식이란 제약이 없는 실제 세계 장면의 영상에 대하여 컴퓨터가 그 안에 포함된 물체를 일반적인 명칭으로 인식하는 것이다. 일반 물체인식의 최종적인 목표는 ‘그림 1’에 나타내듯이 분할(Segmentation)된 각 영역에 대하여 물체 카테고리의 라벨을 붙이는 것이라 할 수 있다.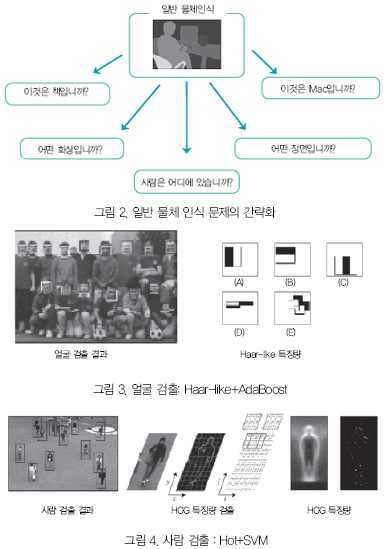 특정 카테고리의 물체 검출에서는 카테고리의 다양함을 억제하기 위하여 특정 카테고리만을 대상으로 하여 대상 카테고리 물체가 화상 어디에 있는가(Localization)를 대답하는 문제로 하고 있다. 한편 화상 분류에서는 대상 물체의 로컬라이제이션(Localization)을 무시하여 화상 중에 인식 대상의 물체가 크게 촬영되어 있다는 조건 하에서 그 물체 카테고리를 선택하는 카테고라이제이션(Categorization) 문제로 하고 있다.
특정 카테고리의 물체 검출에서는 카테고리의 다양함을 억제하기 위하여 특정 카테고리만을 대상으로 하여 대상 카테고리 물체가 화상 어디에 있는가(Localization)를 대답하는 문제로 하고 있다. 한편 화상 분류에서는 대상 물체의 로컬라이제이션(Localization)을 무시하여 화상 중에 인식 대상의 물체가 크게 촬영되어 있다는 조건 하에서 그 물체 카테고리를 선택하는 카테고라이제이션(Categorization) 문제로 하고 있다.
 또한 얼굴이나 사람 등의 물체 검출에서는 국소 특징량 간의 공기성을 고려하는 것으로 인식률을 향상시키는 방법이 제안되어 있으며 Low-Level한 국소 특징량을 통계적 학습 방법을 사용하여 어떻게 조합시킬지, 어떻게 고정시킬지가 중요한 과제가 되고 있다.
또한 얼굴이나 사람 등의 물체 검출에서는 국소 특징량 간의 공기성을 고려하는 것으로 인식률을 향상시키는 방법이 제안되어 있으며 Low-Level한 국소 특징량을 통계적 학습 방법을 사용하여 어떻게 조합시킬지, 어떻게 고정시킬지가 중요한 과제가 되고 있다.