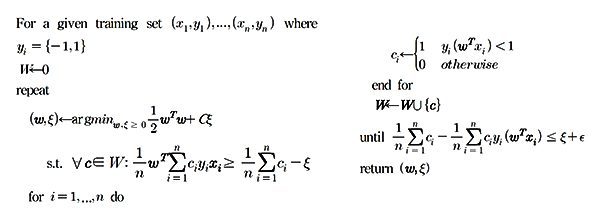| 지능형 CCTV 구현 기본기술 : 영상기반 객체검출 | 2015.05.17 | |||||||||||||||||||
GPU와 CPU를 활용한 객체 검출 알고리즘 성능 비교
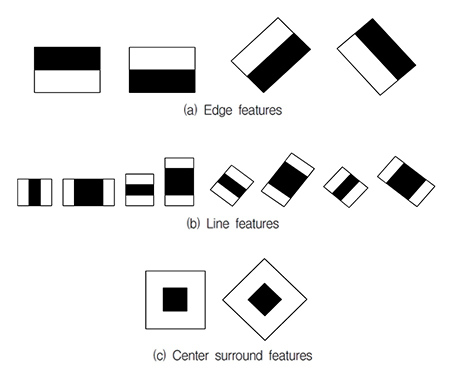
현재 CCTV는 방범, 방재, 시설물 관리, 교통체계 관리 등에 널리 적용되고 있다. 방범·방재를 위한 CCTV 관제센터의 경우 수백 대의 카메라로부터 영상을 전송받기 때문에 평균 20명도 안되는 관제인원이 모든 카메라를 관제하기에는 무리가 따른다. 따라서 최근에는 영상처리, 영상인식 기술을 활용해 범죄나 재난 상황을 인식하는 영상기반 지능형 CCTV 기술이 개발되고 있다[1-4]. 영상기반 지능형 CCTV 관제 시스템을 구현하기 위해서는 객체 검출, 추적, 상황인식 기술이 필요하다. 객체 검출은 영상기반 상황 인식을 위해 필요한 기본 기술이다. 객체 검출을 위해서는 배경추정 기법을 이용하는 방법과 특징점(feature)을 활용해 학습 알고리즘을 이용하는 방법이 있다. 여기에서는 GPU를 활용해 지능형 CCTV 관제 시스템에서의 보행자 검출 속도를 개선하는 방법을 소개하고자 한다. 보행자 검출에 널리 적용되고 있는 Adaboost와 SVM 알고리즘을 CPU와 GPU 상에서 구현해 검출 처리 속도를 비교한다. 엔비디아사(NVIDIA)의 CUDA를 활용해 각 알고리즘을 GPU 상에서 구현, 두 알고리즘의 처리 속도를 CPU와 비교했다. 영상기반 객체 검출 영상기반 객체 검출을 위해 다양한 특징점과 학습 알고리즘이 제안되고 있다. 최근까지 주로 연구되고 있는 특징점들은 유사 Haar 특징점, HOG 특징점, LBP 특징점 등이 있다. 언급한 특징점과 조합해 최근까지 적용되고 있는 학습 알고리즘은 Adaboost 알고리즘, SVM 알고리즘이 주로 사용되고 있다. 영상기반 객체 검출 특징점 영상기반 객체 검출을 위한 특징점 선택은 객체 검출 성능에 많은 영향을 준다. 그림 1은 기본형 유사 Haar 특징점을 나타낸 것이다. (a), (b), (c)는 각각 경계선 특징점, 선 특징점, 중심 특징점이다. 그림 2는 유사 Haar 특징점을 활용해 객체를 검출하는 원리를 나타낸 것으로 보행자의 각 움직임에 대해 유사도가 높은 특징점을 나타낸 것이다.
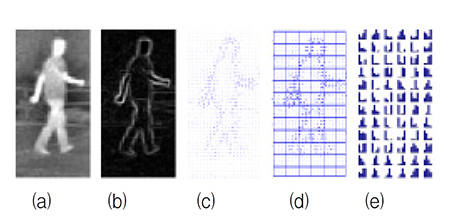
▲그림 2. 보행자를 포함하는 영역에서 높은 응답을 제공하는 유사Haar 특징점 그림 3은 HOG 특징점을 얻는 과정을 나타낸 것이다. (a)는 야간에 촬영된 보행자 영상이며, (b)는 기울기를 검출한 결과이고, (c)는 기울기 방향을 표시한 것이다. (d)는 보행자 영상을 일정한 간격으로 영역을 설정한 것이며, (e)는 각 영역에 대한 기울기 방향의 히스토그램을 나타낸 것이다. 보행자에 대한 기울기 방향 히스토그램은 HOG 특징을 비교해 보행자를 검출하는데 활용한다. 일반적으로 보행자 검출에 효과적인 특징점으로 알려져 있다.
▲그림 3. HOG를 이용한 영상 특징 묘사
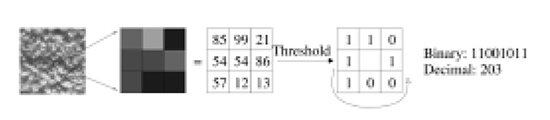
▲그림 4. 기본적인 LBP 연산
그림 4는 LBP 특징점을 구하는 과정을 나타낸 것이다. 특정 영역에서 중심 화소를 기준으로 밝기값이 큰 화소는 1로, 작은 화소는 0으로 설정해 반시계 방향으로 생성된 비트 패턴을 특징점으로 활용한다. 학습 알고리즘 객체의 형상 변화가 있거나 겹침이나 잡음이 있는 상황에서는 학습 알고리즘을 이용한 객체를 검출 방법이 제안되고 있다. 표 1은 보행자와 얼굴 검출에 활용되고 있는 Adaboost 알고리즘이다. 3단계에서 구한 약분류기들을 조합해 4단계에서는 강분류기를 형성해 특정 영역에 대한 유사 Haar 특징점이나 HOG 특징점을 비교해 보행자를 검출한다.
GPU 임베디드 시스템, GPU 테그라 K1 그래픽 또는 영상처리를 위한 CPU의 부하를 줄이기 위해 그래픽 프로세서인 GPU 사용되고 있다. 최근 멀티코어 CPU의 보급과 GPU의 성능 향상에 따라 개인용 컴퓨터에서 병렬처리가 가능하게 됐다. GPU는 엔비디아사와 AMD 등이 활발하게 연구개발을 진행하고 있다.
▲그림 5. CPU와 GPU에서 Adaboost
엔비디아 사의 테그라 K1(Tegra K1) SoC를 사용한 모바일 임베디드 시스템을 활용해 영상기반 객체 검출 시스템을 구현한다. 테그라 K1은 192개의 GPU 코어를 가지고 있어 그래픽 처리 기능이 우수하고 전력 효율이 높다. 테그라 K1은 엔비디아의 Kepler 아키텍처(architecture)로 구현됐으며, DirectX11과 OpenGL 4.4를 지원해 PC 수준의 게임에 그래픽 처리를 지원한다. 레노보 ThinkVision, 샤오미 MI 패드, 에이스 크롬북, HP 크롬북에 적용되고 있다[10]. 테그라 K1은 CPU, GPU, ISP(Image Signal Processor)가 함께 내장되어 있다. CPU는 엔비디아의 2.32GHz ARM 4코어 Cortex-A15이며, GPU는 Kepler GK20a로써 192개의 SM3.2 CUDA 코어를 포함한다. 테그라 K1에 적용된 Kepler GPU의 아키텍처는 고급 시스템에 사용되는 Kepler GPU 아키텍처와 거의 동일하지만, 모바일의 특성상 전력 효율을 유지하고, 모바일 시스템에 맞는 최적화가 적용됐다. 일반적으로 데스크탑, 워크스테이션, 슈퍼 컴퓨터에 적용되는 Kepler GPU는 최대 2,880 개의 단정도 부동 소수점 CUDA 코어를 포함하고 수백 와트의 전력을 소비한다. 테그라 K1 의 Kepler GPU는 192 개의 CUDA 코어로 구성돼 2W 미만을 소비한다. Kepler 아키텍처는 GPC(Graphics Processing Cluster), SMX(Streaming Multiprocessor) 및 메모리 컨트롤러로 구성된다. Kepler 기반 데스탑용 GeForce GTX 680 GPU는 GPC 4개, SMX 8개, 메모리 컨트롤러 4개로 구성된다. 테그라 K1의 Kepler GPU는 GPC 1개, SMX 1개, 메모리 인터페이스로 이루어져있다. 테그라 K1 GPU에는 4개의 ROP가 포함되어 있으며, ROP와 메모리 인터페이스 사이에 128 KB L2 캐시가 있다. 테그라 K1의 Kepler GPU는 OpenGL 4.4 사양과 NVIDIA CUDA 6, 하드웨어 특징 레벨 11로 DirectX 11.2 API를 지원함으로써 모바일 그래픽 처리 기능을 제공한다. 카메라 입력 영상에 대한 처리에 있어 테그라 K1에는 최대 100메가픽셀 센서를 지원하는 듀얼 ISP(dual Image Signal Processor) 코어를 포함하고 있다. 코어에는 4096개의 동시 초점을 처리하고 초당 1.2 G의 화소를 처리할 수 있다. 각 ISP 코어는 공간 변수 노이즈 감소, 다중 불량 화소 수정, 다운 스케일링, 색공간 변환기, 영역 프로세서 등의 기능을 통해 화질을 보정하고 잡음이 적은 영상을 제공함으로써 영상을 기반으로 하는 영상처리 및 컴퓨터 비전 알고리즘의 성능을 향상시킬 수 있다. ISP는 최대 4,096 개의 초점을 사용해 자동 포커스, 포커스 타임, 저조명 포커스 등의 포커스 기능을 제공한다. CUDA 아키텍처 GPU를 단순히 화면 처리뿐만 아니라 병렬처리 계산에 활용하는 방법으로 GPGPU(General Purpose Computing on GPU)가 있다. GPGPU는 GPU를 개발하는 NVIDIA 사의 CUDA(Computer Unified Device Architecture)가 있으며, AMD사의 ATI Stream 등이 있다. 또한 CPU, GPU, DSP 이종의 프로세서로 구성된 하드웨어 플랫폼을 효율적으로 이용하고 플랫폼에 의존하지 않는 응용 프로그램을 개발하기 위한 플랫폼으로 애플사(Apple)에 의하여 제공되는 개방 표준 규격인 OpenCL(Open Computer Language)이 있다. 여기에서는 영상기반 객체 검출을 위해 NVIDIA의 테그라 K1 SoC를 사용하기 때문에 NVIDIA의 전용 플랫폼인 CUDA를 활용한다. CUDA는 GPU에서 수행하는 알고리즘을 C 언어 등의 산업표준 언어로 작성하고 개발할 수 있도록 하는 GPGPU 기술이다. CUDA는 CUDA GPU내부의 명령어 세트와 대용량 병령처리 메모리 접근(Memory Access)을 지원한다. 실험 결과 및 검토 그래픽 병렬처리 SoC 테크라 K1을 탑재한 임베디드 시스템를 활용해 Adaboost 알고리즘과 SVM 알고리즘에 대해 보행자 검출 처리 속도를 비교 분석했다. GPGPU로 CUDA 6.0을 사용해 객체 검출 알고리즘을 컴파일했다. 실험에 사용한 동영상의 해상도는 720×480이다. 그림 5와 6은 각각 유사 Haar 특징점을 이용한 Adaboost 알고리즘과 HoG 특징점을 이용한 SVM 알고리즘에 대해 CPU와 GPU에서 검출한 결과다. 각 알고리즘을 CPU나 GPU로 구현해 보행자를 검출하니 대체로 잘 검출하는 것을 확인할 수 있다.
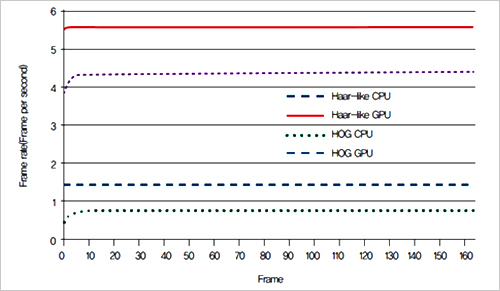
▲그림 7. CPU와 GPU를 사용한 검출 속도 비교
두 특징점을 활용한 검출처리 속도를 비교하면 CPU에 비해 GPU가 약 4배 정도 빠르게 처리하는 것을 확인할 수 있다. 유사 Haar 특징점과 HOG 특징점을 이용한 검출 속도를 비교하면 Haar 특징점을 이용한 Adaboost 알고리즘이 HOG 특징점을 이용한 SVM에 비해 1 프레임 정도 빠르게 처리할 수 있음을 확인할 수 있었다. [글_박장식 경성대학교 전자공학과 교수] [참고문헌] [1] H-M. Moon and S-B. Pan, "The human identification method in video surveillance system," J. of The Korean Institute of Information Technology, vol. 8, no. 5, May 2010, pp. 199-206. [2] H-M. Moon and S-B. Pan, "The analysis of de-identification for privacy protection in intelligent video surveillance system," J. of The Korean Institute of Information Technology, vol. 9, no. 7, July 2011, pp. 189-200. [3] H.-T. Kim, G.-H. Lee, J.-S. Park, and Y.-S. Yu, "Vehicle detection in tunnel using Gaussian mixture model and mathematical morphological processing," J. of The Korean Institute of Electronic Communication Sciences, vol. 7, no. 5, Oct. 2012, pp. 967-974. [4] M.-W. Kim, C.-M. Oh, D. Aurrahman, Y.-G. Ahn, and C.-W. Lee, "The virture screen using skin tone and GMM foreground segmentation," In Proc. Conf. of The Korea Information Processing Society, vol. 15, no. 1, May 2008, pp. 179-181. [5] C. Stauffer and W. E. L. Grimson, "Adaptive background mixture models for real-time tracking," In Proc. IEEE Computer Vision and Pattern Recognition(CVPR) 1999, vol. 2, June 1999, pp. 246-252. [6] A. Elgammal, D. Harwood, and L. S. Davis, "Non-parametric model for background subtraction," In Proc. European Conf. on Computer Vision(ECCV 2000), vol. 1843, June. 2000, pp. 751-767. [7] T. Ahonen, A. Hadid and M. Pietikaninen, “Face description with local binary patterns : application to face recognition,” IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 28, no. 12, Dec. 2006. pp. 2037-2041. [8] D. Geronimo, A. D. Sappa, A. Lopez and D.Ponsa, “Pedestrian detection using Adaboost learning of features and vehicle pitch estimation,” In Proc. Int. Conf. Visualization, Imaging and Image Processing(IASTED), Palma de Mallorca, Spain, Aug. 2006. pp. 400-405. [9] Thorsten Joachims, “Training linear SVMs in linear time,” In Proc. of Int. conf. on Knowledge Discovery and Data Mining(KDD), Philadelphia Pennsylvania, Aug. 2006. pp. 217-226. [10] “NVIDIA Tegra K1, A New Era in Mobile Computing,” White-paper of NVIDIA, 2013. <저작권자: 보안뉴스(http://www.boannews.com/) 무단전재-재배포금지> |
||||||||||||||||||||
|
|